
MLOps and DataOps - Building Human Trust in AI through ML and Data Infrastructure
What an AI feature store startup CEO taught me about the industrialization of artificial intelligence

“In the next 2-3 years, best-in-class ML developer tools will emerge,” says the founder of an open-source MLOps project, “infrastructure standardization paves the way for verticalized winners.”
The future of MLOps and DataOps is headed towards the standardization of ML tooling, emphasis on developer experience through open sourcing, abundant opportunities in data management and collaboration, and more product-vision-driven verticalized winners.
Why do we care about MLOps and DataOps? The maturity of MLOps and DataOps is a leading indicator of the age of AI for two reasons. One, maturing infrastructure accelerates the go-to-market of novel AI applications. And two, the industrialization of AI means more standardized, reliable, and trustworthy AI.
For those who came to get quick answers:
Will there be more AI? Yes, the world’s data is growing at 19% CAGR to 180 zettabytes in 2025 - that’s fertile ground for AI.
Will AI make AI? Yes, ML tools are being developed to automate the production process of AI, aka the intelligence industrialization.
Can we trust AI? Yes and no, monitoring tools for ML drifting and data quality can help, but work remains to be done to remove biases from AI models.
AI now makes judgments that are deeply human. AI gets to decide whether a mother gets a home mortgage to raise her kids, whether a school teacher gets the job, and whether a doctor should recommend surgery to a patient. Ultimately, the adoption of AI begs the question — how can we trust AI?
How can we trust AI? Ironically, to trust AI, we as humans must remove ourselves from the production process of AI, so that AI can be iterated, monitored, and improved. In classic industrialization, manufacturing went from humans making machines to machines making machines. Quality and output went up as a result. In the ongoing AI industrialization, machine learning is going from humans making AI to AI making AI. To build trust in AI, developers are at the center of this evolution as artisans of intelligence — producing infrastructure developer tools that are important to the automation of data feed and to the iteration of AI in trends shown below.
State of MLOps and DataOps
Fertile Ground: Abundant Data and Maturing AI Infrastructure Paving the Way for Buy over Build
Companies have more data than they know what to do with. Across the world, 64 zettabytes of data were created in 2020. It is estimated that this number will grow at 32% CAGR to 180 zettabytes in 2025 - that is equal to 22 terabytes of data created for every person on earth. 50% of all data will be stored in the cloud, meaning data will become more accessible. Adding to this explosion of data, AI is turning unstructured data into structured data, to be accessed, searched, and operationalized.
The next generation of data will be synthetic. Synthetic data will asymmetrically benefit smaller companies that lack the scale of tech giants and companies in privacy-centric industries in which production data is guarded. Synthetic data will fill in the blank for industries in which data is scarce or protected. ML project managers will have a choice to buy data rather than build their own data sources.
Two loops make up the industrialization of AI: the ML Loop that supplies the model and the Data Loop that supplies data. Building an ML Loop without the Data Loop is like opening a university with no textbooks. The Data Loop operationalizes data by continuously accessing, preparing, and feeding data into the ML Loop. Because data stores are siloed, data tech is legacy, and data collaboration platforms are nascent, DataOps developer tools hold many challenging problems to solve and much economic value to unlock.
AI infrastructure is maturing with 870 AI-related mergers, acquisitions, and IPO’s, between 2016-2020. Pitchbook reported a record surge in AI mega-exits, totaling $153 billion across 26 exits. Winners are emerging in each category of MLOps — the standardization and reliability of MLOps will empower more companies to buy rather than build AI. As consolidation continues, best-in-class tools are emerging as standards in their respective fields shown in the landscape below.
Who’s who? A Thriving Data Infra and MLOps Ecosystem
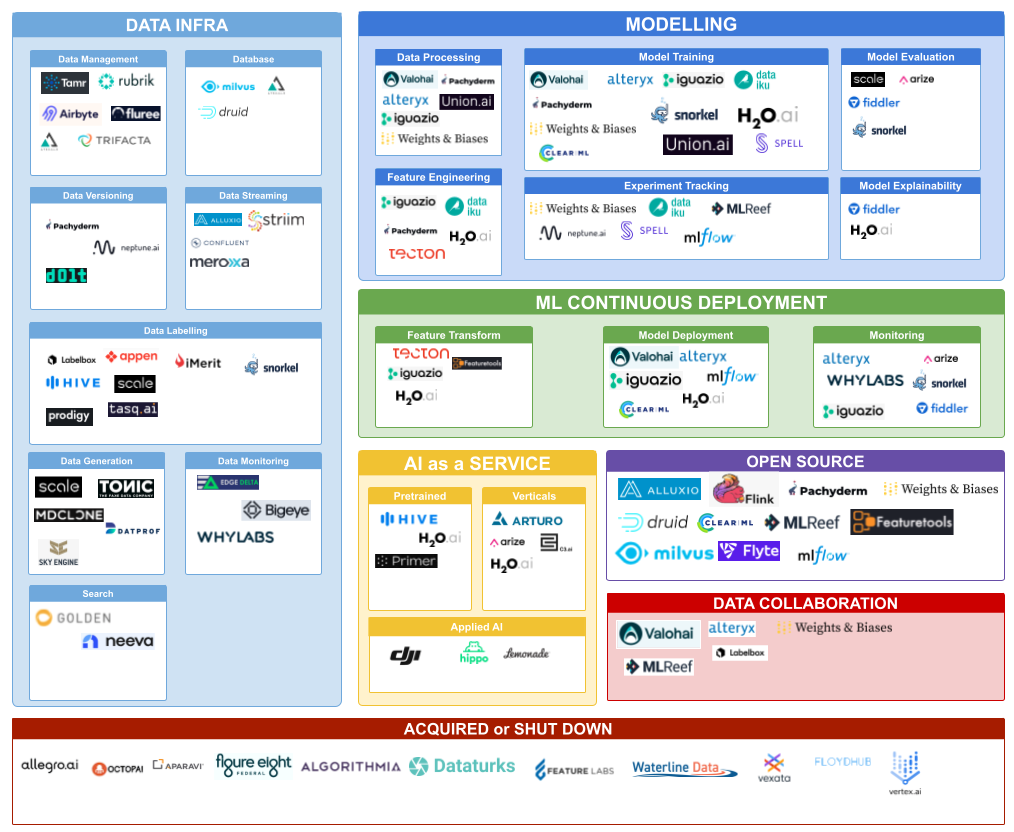
Companies to Watch in DataOps
AtScale - The Series D company provides a semantic layer for data analysis. A semantic layer maps complex data into familiar business terms such as product, customer, or revenue to offer a unified consolidated view of data across the organization.
Labelbox - The A16Z and In-Q-Tel invested company provides collaboration and management of data labeling workforces. It is emerging as a winner along with ScaleAI in the data labeling category. Enterprise data is sensitive and the avoidance of potential rivals such as Amazon and Microsoft opens pathways for data labeling companies to scale by virtue of data network effects.
Alluxio - The San Mateo company provides a data orchestration layer for AI/ML and big data, innovating on a global namespace, intelligent multi-tiering caching, and server-side API translation. An orchestration layer consolidates data across siloes.
TonicAI - The “Fake Data Company” provides synthetic data that looks like the real deal. It removes the risk and privacy concerns of using production data for model development. Synthetic data can democratize access to AI for smaller players that don’t have billions of users.
Striim - The Palo Alto-based company exemplifies the evolution from ETL to data streaming. Striim continuously ingests a wide variety of high-volume, high-velocity data and performs in-flight data processing such as filtering, transformations, aggregations, masking, and enrichment of streaming data in the cloud or on-prem.
Companies to Watch in Open Source
Milvus - This project with 8k likes on GitHub provides vector databases for unstructured data. Its databases are good for unstructured data such as emails, papers, IoT sensor data, photos, and protein structures. As a kicker, Milvus allows a fast vector search to make unstructured data accessible.
Druid - The Apache distributed data store project combines ideas from data warehouses, time-series databases, and search systems to create a high-performance real-time analytics database. It typically sits between a storage layer and the end-user and acts as a query layer to serve analytic workloads.
Pachyderm - The open-sourced company provides data versioning based on an object storage backend, allowing developers to commit data as they would code. This capability allows models to be retrained based on the presence of new data. The San Francisco company received venture funding from DCVC and Benchmark.
Weights and Biases - The growth-stage company provides tools to track experiments, collaborate between data teams, and visualize results. It is one of the contestants to become the google doc for ML teams.
Companies to Watch in MLOps
Snorkel - The Series C company started in data labeling, and quickly expanded into ML functional areas and verticalized solutions. Data labeling benefits from the data network effect. The more customer workload, the better the labeling automation.
Arize - The early-stage company helps ML teams assess performance, compare to ground truth, increase observability, monitor drift, and troubleshoot issues. Arize has highlighted a few use cases such as credit decisioning, demand forecasting, fraud detection, algorithmic trading, and image classification.
Tecton - The San Francisco company specializes in feature stores and feature engineering. Feature stores can be understood as the interface between models and data. Raw data must be turned into features before an ML model can ingest for training and production.
A Recap on the History of MLOps and DataOps
DevOps Laid the Groundwork for Deployment Automation
The DevOps movement started to coalesce some time between 2007 and 2008. The rise of SaaS and Agile set the stage for deployments on a weekly or even hourly cadence. Such a frequent, iterative approach to software required novel infrastructure techniques and platforms needed to be invented to smoothly ship production code.
The seminal moment for DevOps came at a Flickr conference, where two employees role-played Dev and Ops in a skit titled “10+ Deploys per Day: Dev and Ops Cooperation at Flickr”. From there, the development of DevOps led to infrastructure as code, environment as code, and configuration as code. DevOps deferred from previous deployment management tools because it is tooling made by developers for developers.
MLOps and DataOps are a Single Platform for Developers + Data Scientists + Operations
Then, in 2015, the origin of MLOps was marked by a paper titled “Hidden Technical Debt in Machine Learning Systems”. The author found massive ongoing maintenance costs in real-world ML systems. “Prediction” implied true scale, production-level deployment, monitoring, and updating. Without MLOps, data scientists were stuck in the notebook - literally emailing Python models to engineers for production deployment and code rewrites.
MLOps is a discipline for collaboration and communication between data scientists, software developers, and operations to eliminate waste and make machine learning systems more scalable by providing automation and by producing highly consistent insights from the ML model.
As mentioned above, MLOps is intertwined with DataOps. Because ML logic is learned, not written, data lies at the core of machine learning systems. However, existing data infrastructure is often siloed or legacied. Reliably obtaining, cleaning, integrating, accessing, evaluating, transforming, and storing data becomes a real challenge.
In 2014, the term DataOps was coined by Lenny Liebmann in a blog post titled “3 reasons why DataOps is essential for big data success”. DataOps provides a single platform for data scientists, analysts, ETL engineers, IT and QA to increase velocity, reliability and quality of data.
Already, novel concepts such as data version control and feature store have sprung up in the past several years. But we are still at the beginning of the century of data-driven intelligence. The challenge in managing and operationalizing data will continue for the next several decades.
Benchmarking - AI Surpassed Humans and Competes Against One Another
AI has reached super-human levels in areas such as image recognition, video games, voice generation, art style imitation and predictions. For example, in 1997, Deep Blue beat Kasparov in chess. In 2015, ImageNet based models bested humans in image recognition. Now that AI has surpassed humans in specific areas, ML models are competing against one another for ever diminishing error rates.
To facilitate an apples-to-apples comparison, benchmarks are set across key ML research areas such as vision, language, and commerce. Given a set of system, processor, accelerator and software, each project can measure itself against a set of records:
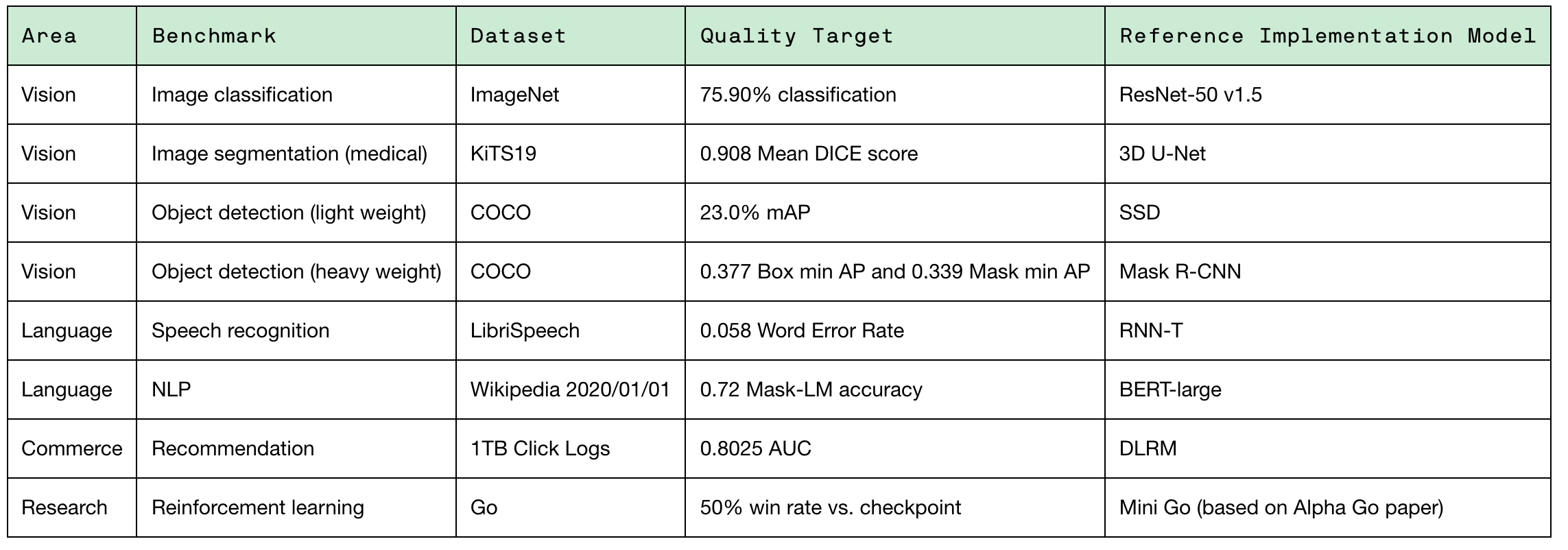
DICE coefficient is the area of overlap divided by the total number of pixels in both images. The higher the DICE score, the more a machine vision algorithm can extract an object of interest from the background. mAP (mean average precision) is the average of ‘true positives’ over ‘ total positive results’.
These benchmarks are important guiding handrails in the automation of AI. As the industry matures, we will develop monitoring tools that help us place trust in AI. For example, tools to monitor bias, tone, and even ethicality in AI-driven judgements.
What trends to watch?
Industrialization of AI Production
As MLOps tools mature, we will see more standardization, modularization, resource conservation, monitoring and higher performance in AI production. LabelBox, Alteryx, Snorkel, H2O, and Dataiku are several winners in this category.
In five to ten years, AI will commoditize and consumerize. Mobile AI, low-code AI, and edge AI are all on the horizon. We can imagine a future in ten years, in which teenagers use smartphones to train their own AI models and share with others as easily as they share photos.
Better Developer Experience from Open Sourcing
Because ML models ingest proprietary data, open sourcing is one way to ensure enterprise buyers that there isn’t funky business in the code. Some examples are Milvus with 8k github likes for its vector database and Pachyderm that provides open source data versioning.
Developer experience is key to the success of wider community adoption. Developer timeshare and mindshare are limited resources - developer network effects are the moat for successful open source projects to pull ahead of competition.
Data Management and Collaboration
Data is exploding and we are under-equipped to keep up. From vector databases (Milvus) to synthetic data (TonicAI), from no-code data orchestration (Tamr) to metadata store (Neptune), I expect more ground-breaking innovation in data management over the next several years.
Winners in this space will find ways to make data more accessible and reliable. Some areas that I’m keeping a close watch on are cloud-based data orchestration, NLP-driven knowledge graphs, and domain-specific data search systems.
Product-Driven Verticalized Winners
As advances in MLOps and DataOps lay the foundational rails for AI, the next wave of startups can speed up their AI go-to-market. In the previous decade, the advent of mobile and cloud gave rise to mobile-first superstars such as Stripe and Uber.
In the next decade, the maturation of machine learning and data infrastructure will propel ambitious teams to delight their customers by building visionary AI products.
Thanks for reading - shout out to Willem Pienaar and Jonah Cader for the input. What did I miss? I’d love to hear from you - holler at me on LinkedIn and Twitter.